炼丹术——可变学习率训练
学习率对网络训练的效果影响很大,一般来看,越到后面,学习率要越小,手动可以调节,但可变学习率会更方便。还有一种更骚的操作是warm up学习,学习率早期先增大预热,再减小。
一、不变学习率
设定学习率为0.01,训练30个epoch,batch_size=128。发现15个epoch之后训练变缓,因此可以在次改变学习率。最终的训练集86.1%,测试集集83.3%
#############1. 数据准备
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchvision import transforms,datasets
datapath = '/home/Dataset/cifar10_data'
train_transform=transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),
])
test_transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])
train_data= datasets.CIFAR10(root=datapath,train = True,transform = train_transform)
test_data = datasets.CIFAR10(root=datapath,train = False,transform =test_transform)
###############2.模型准备
class VGG(nn.Module):
def __init__(self):
super(VGG, self).__init__()
self.conv1 = nn.Conv2d(3, 32, 3, 1, 1,bias=False)
self.conv2_1 = nn.Conv2d(32, 64, 3, 1, 1,bias=False)
self.conv2_2 = nn.Conv2d(64, 64, 3, 1, 1,bias=False)
self.conv3_1 = nn.Conv2d(64, 128, 3, 1, 1,bias=False)
self.conv3_2 = nn.Conv2d(128, 128, 3, 1, 1,bias=False)
self.conv3_3 = nn.Conv2d(128, 128, 3, 1, 1,bias=False)
self.fc1 = nn.Linear(2048, 128,bias=False)
self.fc2 = nn.Linear(128, 10,bias=False)
def forward(self, x):
out = F.relu(self.conv1(x))
out = F.max_pool2d(out, 2)
out = F.relu(self.conv2_1(out))
out = F.relu(self.conv2_2(out))
out = F.max_pool2d(out, 2)
out = F.relu(self.conv3_1(out))
out = F.relu(self.conv3_2(out))
out = F.relu(self.conv3_3(out))
out = F.max_pool2d(out, 2)
out = out.view(out.size(0), -1)
out = F.relu(self.fc1(out))
out = self.fc2(out)
return out
net = VGG()
device = 'cuda' if torch.cuda.is_available() else 'cpu'
net = net.to(device)
from torchsummary import summary
summary(net,(3,32,32))
##############3.参数设置
epochs = 30
lr = 0.01
optimizer = torch.optim.SGD(net.parameters(), lr=lr, momentum=0.9, weight_decay=5e-4)
batch_size = 128
train_loader = torch.utils.data.DataLoader(train_data,batch_size=batch_size,shuffle=True,drop_last=True)
test_loader = torch.utils.data.DataLoader(test_data,batch_size=batch_size,shuffle=False,drop_last=False)
#################### 4.测试函数
def test():
net.eval()
test_loss = 0
correct = 0
total = 0
with torch.no_grad():
for batch_idx, (inputs, targets) in enumerate(test_loader):
inputs, targets = inputs.to(device), targets.to(device)
outputs = net(inputs)
loss = criterion(outputs, targets)
test_loss += loss.item()
_, predicted = outputs.max(1)
total += targets.size(0)
correct += predicted.eq(targets).sum().item()
#print('[Test] Loss: %.3f | Acc: %.3f%% (%d/%d) lr=%.4f' % (test_loss/(len(test_loader.dataset)/100), 100.*correct/total, correct, total,scheduler_warmup.get_lr()[0]))
print('[Test] Loss: %.3f | Acc: %.3f%% (%d/%d) lr=%.4f' % (test_loss/(len(test_loader.dataset)/100), 100.*correct/total, correct, total,lr))
####################5. 训练
net.train()
## Loss and optimizer
criterion = nn.CrossEntropyLoss()
best_acc =0
for epoch in range(epochs):
train_loss = 0
correct = 0
total = 0
print('epoch %d:'%(epoch),end="")
for batch_idx, (inputs, targets) in enumerate(train_loader):
inputs, targets = inputs.to(device), targets.to(device)
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, targets)
loss.backward()
optimizer.step()
train_loss += loss.item()
_, predicted = outputs.max(1)
total += targets.size(0)
correct += predicted.eq(targets).sum().item()
print('[Train] Loss: %.3f | Acc: %.3f%% (%d/%d)'% (train_loss/(batch_idx+1), 100.*correct/total, correct, total),end="")
test()
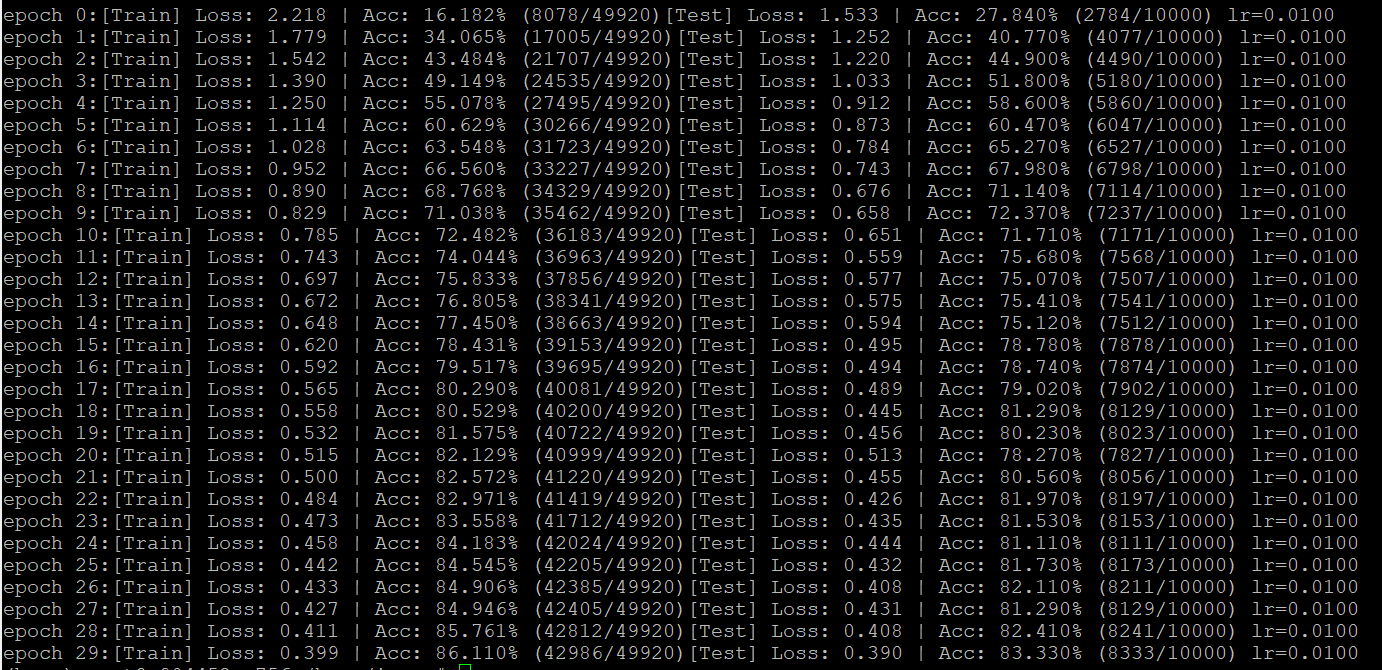
二、学习率衰减
调整学习率需要导入'lr_scheduler'的包,调整选项,比如StepLR,ExpontialLR,MultiStepLR等,详情见链接。有实验表明,离散变化的学习率足以表现良好,首先用StepLR,需要修改三个地方: 1.参数设置部分
epochs = 30
# a.导入包
from torch.optim import lr_scheduler
lr = 0.01
optimizer = torch.optim.SGD(net.parameters(), lr=lr, momentum=0.9, weight_decay=5e-4)
#b.每16个epoch之后,lr变为原来的0.2
scheduler1 = lr_scheduler.StepLR(optimizer,step_size=16,gamma=0.2)
#scheduler1 = lr_scheduler.ExponentialLR(optimizer, gamma=0.95) # 每个epoch,lr变为原来的0.95
#scheduler1 = lr_scheduler.MultistepLR(optimizer,milestones=[10,20],gamma=0.5)# 10epoch后变为原来0.5,20 epoch后又衰减0.5
batch_size = 128
train_loader = torch.utils.data.DataLoader(train_data,batch_size=batch_size,shuffle=True,drop_last=True)
test_loader = torch.utils.data.DataLoader(test_data,batch_size=batch_size,shuffle=False,drop_last=False)
- 测试集输出
# c.通过scheduler1.get_lr()[0])查看当前学习率
print('[Test] Loss: %.3f | Acc: %.3f%% (%d/%d) lr=%.4f' % (test_loss/(len(test_loader.dataset)/100), 100.*correct/total, correct, total,scheduler1.get_lr()[0]))
#print('[Test] Loss: %.3f | Acc: %.3f%% (%d/%d) lr=%.4f' % (test_loss/(len(test_loader.dataset)/100), 100.*correct/total, correct, total,lr))
- 训练集更新
print('[Train] Loss: %.3f | Acc: %.3f%% (%d/%d)'% (train_loss/(batch_idx+1), 100.*correct/total, correct, total),end="")
test()
#d.调整学习率
scheduler1.step()
这是lr=0.01,scheduler1 = lr_scheduler.StepLR(optimizer,step_size=16,gamma=0.2)的结果,可见16个epoch减小学习率后,准确率从77% 跳到81%,再缓慢增加。
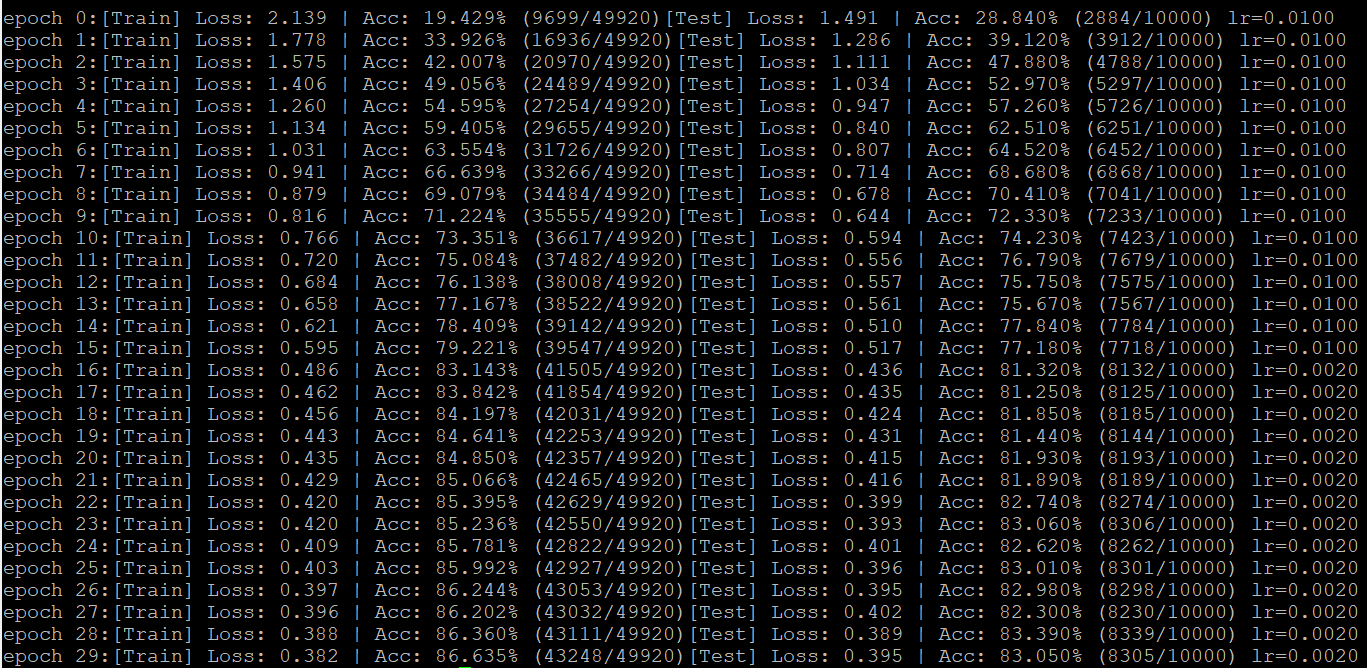
这是lr=0.02,scheduler1 = lr_scheduler.MultistepLR(optimizer,milestones=[10,20],gamma=0.5),可见第10、20epcoch处有2%的准确率跳变。
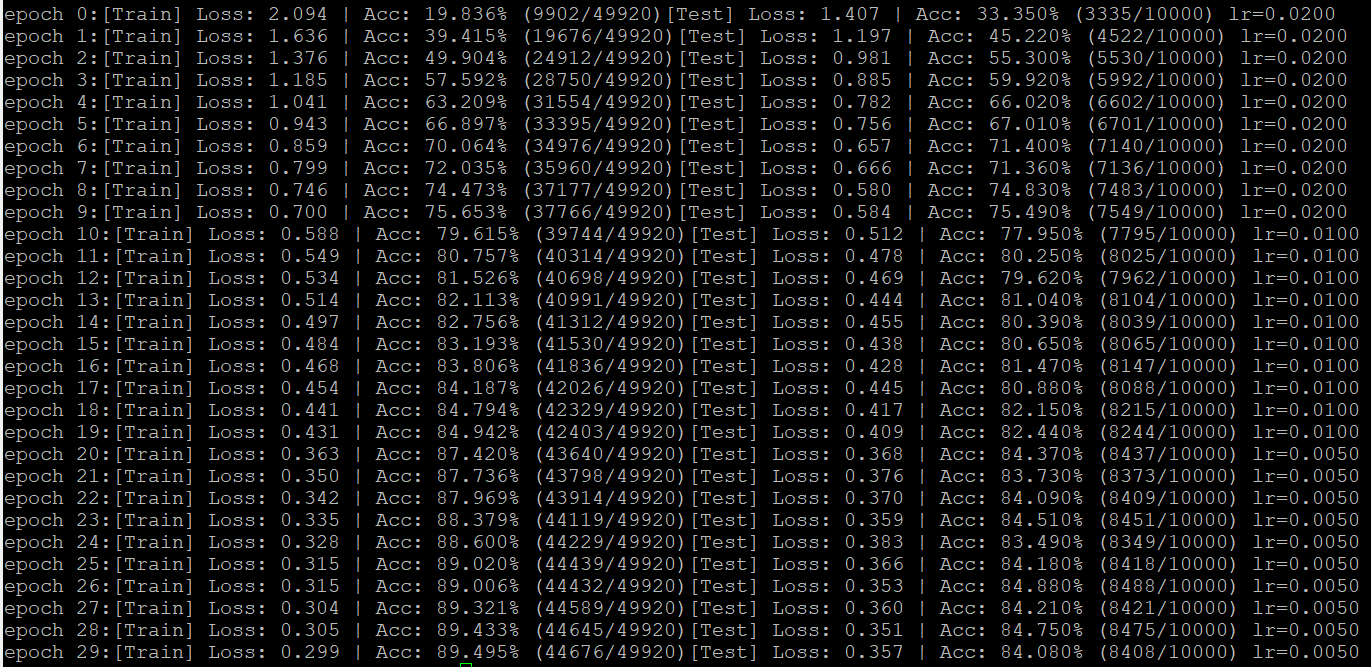
这是lr=0.04,scheduler1 = lr_scheduler.ExponentialLR(optimizer,gamma=0.885),30epoch 之后lr降为0.001。可见准确率增长相对稳定,最终到85%。
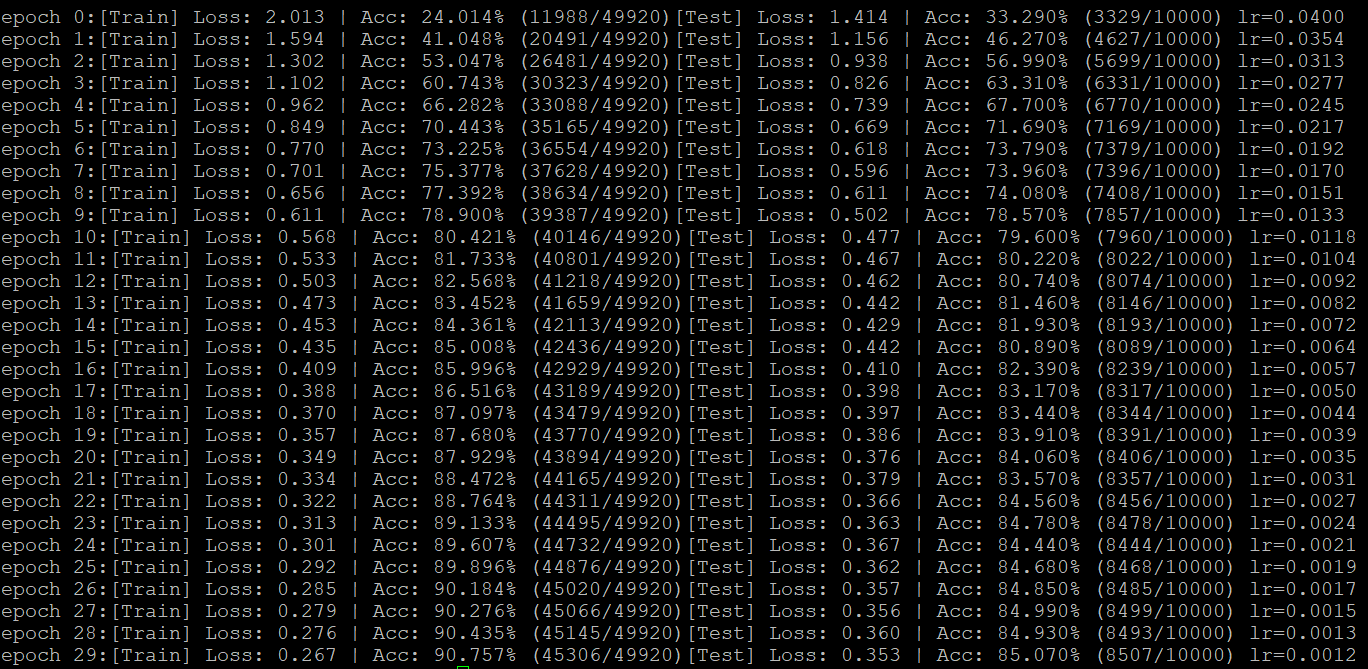
三、warmup学习
warmup 是学习率先快速增大,然后按之前设置的方式衰减,说明和用法在这,先安装warmup包pip install warmup-scheduler,然后也是修改三个地方:
- 参数设置
epochs = 30
from torch.optim import lr_scheduler
#a.导入warmup包
from warmup_scheduler import GradualWarmupScheduler
lr = 0.001
optimizer = torch.optim.SGD(net.parameters(), lr=lr, momentum=0.9, weight_decay=5e-4)
#scheduler1 = lr_scheduler.StepLR(optimizer,step_size=10,gamma=0.2)
#scheduler1 = lr_scheduler.MultiStepLR(optimizer,milestones=[5,10,15,20,25],gamma=0.5)
#scheduler1 = lr_scheduler.ExponentialLR(optimizer, gamma=0.885)
#b.前5个epoch,从0.001增加到0.04,之后按scheduler1变化lr
scheduler_warmup = GradualWarmupScheduler(optimizer, multiplier=40, total_epoch=5, after_scheduler=scheduler1)
batch_size = 128
train_loader = torch.utils.data.DataLoader(train_data,batch_size=batch_size,shuffle=True,drop_last=True)
test_loader = torch.utils.data.DataLoader(test_data,batch_size=batch_size,shuffle=False,drop_last=False)
- 测试集输出
# c.通过scheduler_warmup.get_lr()[0])查看当前学习率
print('[Test] Loss: %.3f | Acc: %.3f%% (%d/%d) lr=%.4f' % (test_loss/(len(test_loader.dataset)/100), 100.*correct/total, correct, total,scheduler_warmup.get_lr()[0]))
#print('[Test] Loss: %.3f | Acc: %.3f%% (%d/%d) lr=%.4f' % (test_loss/(len(test_loader.dataset)/100), 100.*correct/total, correct, total,lr))
- 训练集更新 这下将更新放在前面的位置
net.train()
## Loss and optimizer
criterion = nn.CrossEntropyLoss()
best_acc =0
for epoch in range(epochs):
#d.调整学习率
scheduler_warmup.step()
train_loss = 0
correct = 0
total = 0
这是先warmup到0.4,再每10epoch缩小为原来的0.2。
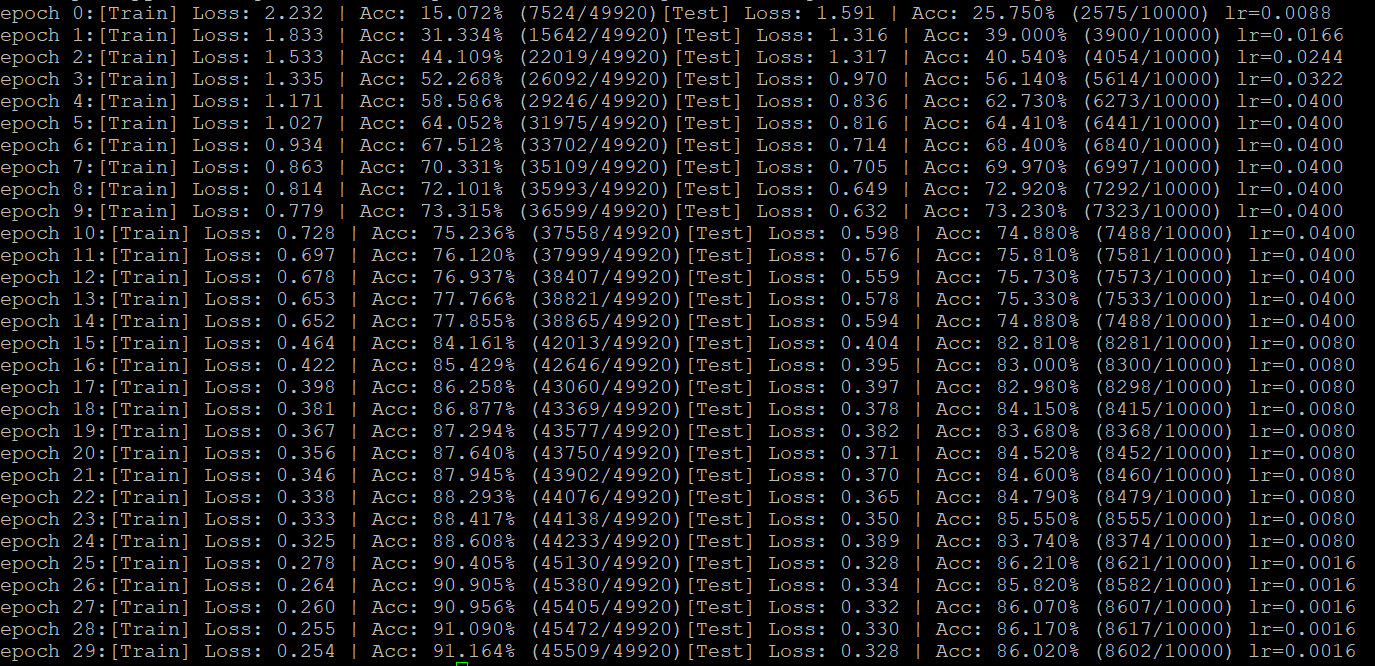
这是先warmup到0.4,在[5,10,15,20,25]的epoch节点上,缩小0.5。
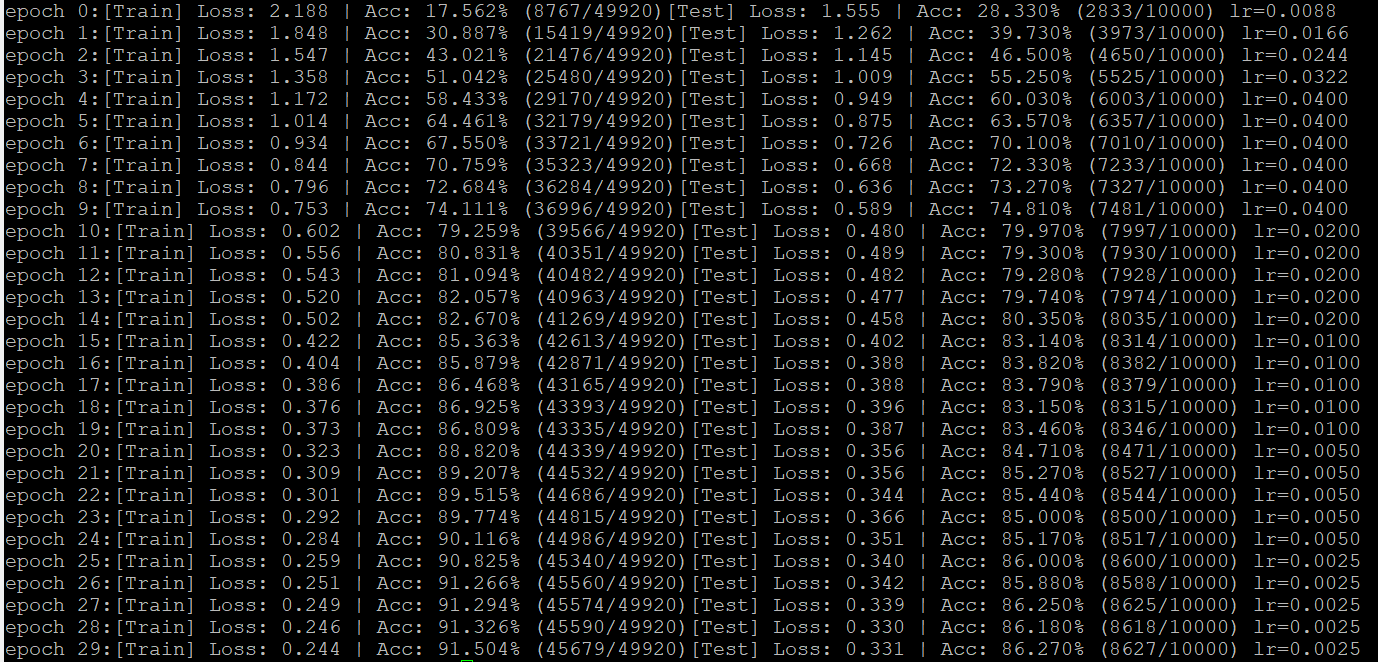
这是先warmup到0.4,每个epoch变为原来的0.885。
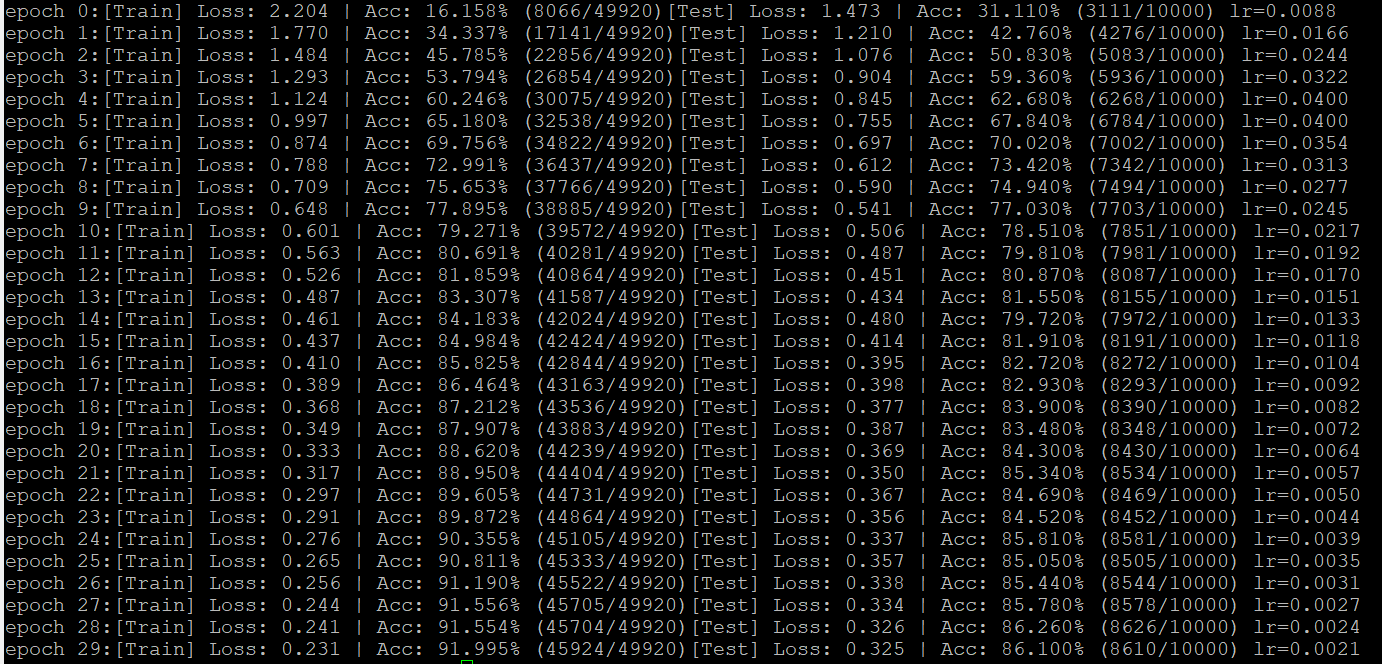
四、小结
简单总结了一下上面的结果,调整学习率确实可以提升训练的效果,但要调好也不简单,比如batch_size,设为256时效果欠佳;比如起始学习率,0.01显然太小了。

最后附上代码:vgg_cifar10_lr_test.zip