内联汇编的妙用
一、问题描述
AES加密模式中,有一种CTR模式,其流程如下图:
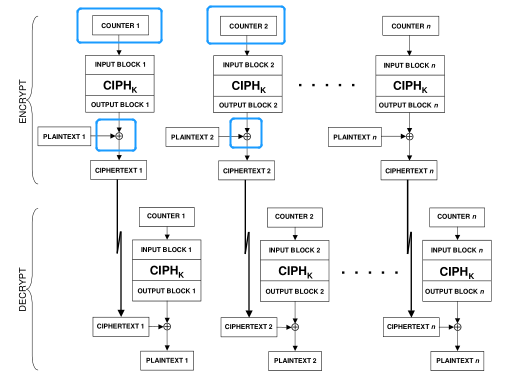
加密时,除了明文和密钥外,还需要一个初始向量COUNTER1,将其加密的结果和明文异或,即可得到密文;下一块明文加密时,COUNTER1加1得到COUNTER2。详情可以查看博文AES的五种加密模式。
以下是我用拓展指令集在AES加速的CTR模式代码,测试的了三块数据,初始向量vi=“0102030405060708”(128bit),但编译之后,加密的结果只有第一块正确,其余两块不正确,vivado查看波形,发现三次的COUNTER没有改变,但最后COUNTER的结果确实加了3,到底是为什么?
int NICE_aesEncrypt_ctr(const uint8_t *key, uint32_t keyLen, const uint8_t *vi,
const uint8_t *pt, uint8_t *ct, uint32_t len)
{
//拷贝初始向量
uint8_t counter[16]={0};
memcpy(counter, vi, keyLen);
uint8_t *pos = ct;
for(int i=0; i二、找bug
代码编译的时候,我采用的是-O2或-O3,在编译器看来,代码中NICE_loadstate((int)counter)和 counter[15]+= 1的counter似乎没有数据冲突,因此编译器做循环展开优化的时候,会分开独立运行这两条指令,所以三块的输入向量没有依次累加,但最后counter连续加了3下。以三个数据块为例,原本的执行顺序是①②①②①②,编译优化后的顺序是①①①②②②,这样得到的结果显然不对。
三、Debug
1、不优化(结果正确)
那么如何让编译器“笨”一些呢,我首先采用的是不加优化,结果确实按顺序累加,结果正确。但总觉得不太爽,毕竟-O2优化非常常用,这里不用,其他地方也得用,不加优化不是长远之计。
2、利用数据相关性(失败)
既然编译器认为数据不相关,那么能不能加些东西,让它数据相关,于是借助循环变量i,做累加操作:
// 5 ctr
int NICE_aesEncrypt_ctr(const uint8_t *key, uint32_t keyLen, const uint8_t *vi, const uint8_t *pt, uint8_t *ct, uint32_t len) {
uint8_t *counter =(char*)malloc(sizeof(char)*16);
memcpy(counter, vi, keyLen);
uint8_t temp =counter[15]; //**增加临时变量**
uint8_t *pos = ct;
int zero=0;
for(int i=0; i结果还是不行。
全网搜了循环展开编译相关的信息,没找到好的解决方案,心有不甘。
3、内联汇编(结果正确)
一觉醒来,梦游搜索一番,内联汇编的想法冒出来,决定一试:既然编译器不能如我所愿,那我就把想要的部分帮编译器先干了! 各种架构在线编译平台 稍微做一些调整,将+1的操作移到前面,不然要写好多汇编...
// 5 ctr
int NICE_aesEncrypt_ctr(const uint8_t *key, uint32_t keyLen, const uint8_t *vi, const uint8_t *pt, uint8_t *ct, uint32_t len) {
uint8_t *counter =(char*)malloc(sizeof(char)*16);
memcpy(counter, vi, keyLen);
uint8_t *pos = ct;
int zero=0;
counter[15]-=1; //**预先处理**
for(int i=0; i完美解决!编译器在这部分没有改变顺序,-O2或-O3优化可以得到正确的结果!
四、小结
山重水复疑无路,柳暗花明又一村。
本想放弃挣扎,没想到灵感骤现,真是“念念不忘,必有回响”,这个小bug将之前学的指令集,汇编等小知识串在一起,多条内联汇编语句可以规定顺序执行,这在软硬件协同设计里面一定能经常用到。