忆阻器阵列学习笔记
最近阅读组里忆阻器阵列的nature文章,搞清楚很多问题,特别是CNN的算法如何在忆阻器上实现这点,特来整理一波。
Fully hardware-implemented memristor convolutional neural network
一、顶层结构
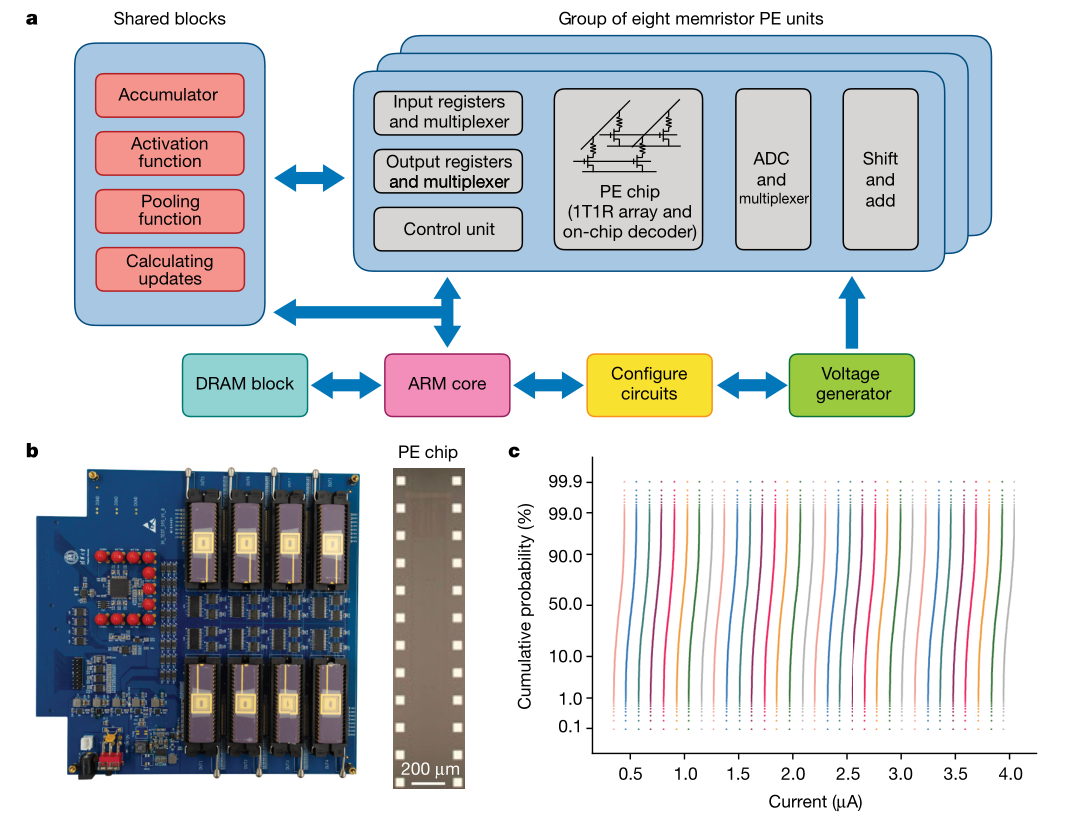
这图包含很多信息量:
- 图a:中间的忆阻器阵列PE chip只做矩阵乘法,得到的电流通过ADC转成数字信号,然后在软件上进行pooling,Activation,Accumulate等操作,再进入下一层卷积网络。(这一点困扰了我很久,我之前以为pooling和Activation也是通过模拟电路实现的,电流在忆阻器间流动,最后才由ADC输出)
- 图b:中间有8个PE阵列,每个阵列有$128\times 16=2048$个1T1R单元
- 图c:这幅图是想告诉我们忆阻器的电导值波动不大。每个忆阻器都施加0.2V的电压,得到的电流就是横坐标X轴,表示不同电导的忆阻器。它们有一个累积概率分布(对,就是概率论里面的累积概率分布F),可见某一电导的方差很小,波动性不大。
二、推理过程数据流
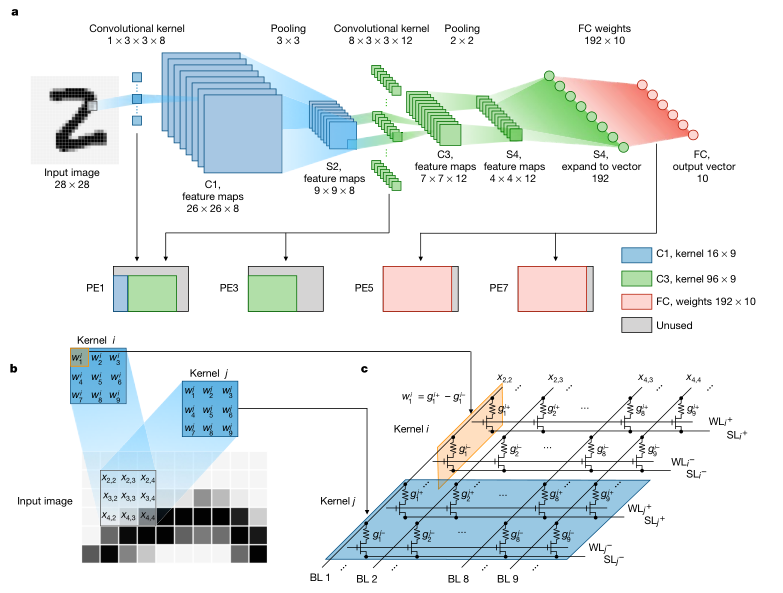 这图介绍了MNIST手写数据集推理过程的算法,以及算法如何映射到忆阻器阵列,非常重要。
这图介绍了MNIST手写数据集推理过程的算法,以及算法如何映射到忆阻器阵列,非常重要。
- 图a:算法上的计算包括卷积1、pooling1、卷积2、pooling2、全连接。第一层卷积$1\times 3\times 3\times 8$有72个权重,为了表示正负,需要引入差分,如图c。所需要的元件加倍,即图a中蓝色图例“$C_1,kernel 16\times9$” 这些权重映射到第一个PE单元中。
- 图a:第一层出来的电流需要经过ADC转成电压,在软件上做pooling和Activation,然后再进入下一层卷积层(这一点和我之前的理解不一样,之前觉得电流会在网络中一直流动,最后分类的时候才出ADC)。所以ADC在外围电路中非常重要,占整体功耗的近90%。
- 图a:第二层也要考虑差分,需要的权重为$8\times3\times3\times12*2=96\times9 *2$,分别映射到PE1和PE3。第三层全连接,需要权重$192\times 10 *2$,分布映射到PE5和PE7。
需要说明的是,各层的权重是在GPU上训练好的,根据一定关系转为电导值,通过“check”的方式确定每个电导和理论的相同,整个过程比较耗时耗力;之后两个卷积层不参与训练,全连接层会参与忆阻器阵列中的训练。
软件训练的测试集精度为97.99%,15level(4bit)量化之后为96.92%,映射到忆阻器上为95.07%,最后训练全连接层,达到96.19%的精度。经过全连接层训练,训练集精度从95.18%增加到96.79%。
混合训练的方式证明有效:随机化这个网络10%的权重,准确率降到80.66%,但用少量数据(10%)训练全连接层,可以恢复到94.40%。ResNet56的网络完成cifar10任务,全精度准确率95.57%,15个level量化后为89.64%,仿真器映射后降到79.76%,用3%的数据训练最后的全连接层,准确率回到92.0%。
三、推理过程电路结构
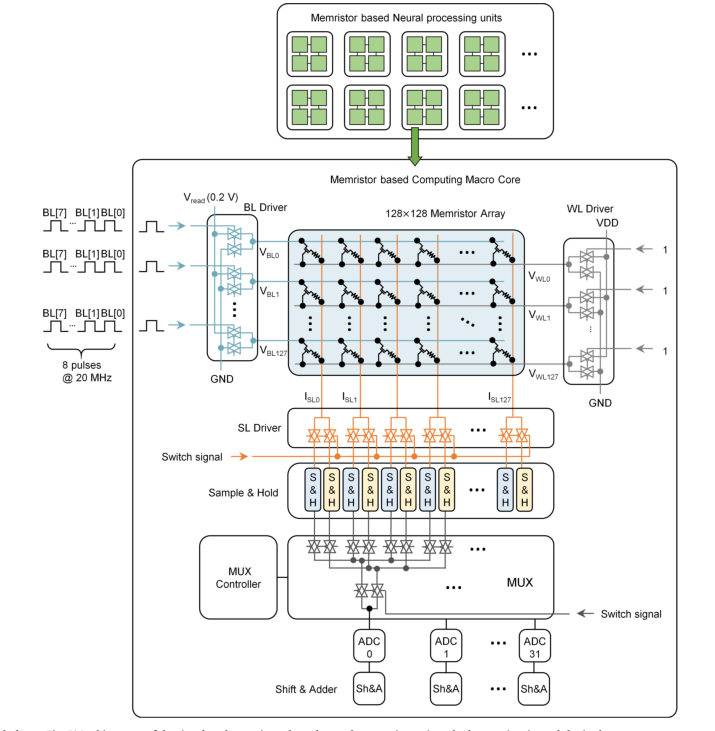
这图最有趣的是输入:8bit的数据是通过8个周期送入阵列的(之前一直以为是一次进入),每次出来的电流会在MUX中做差分,进入ADC,再经过Shift & Adder将八次的结果移位累加,转化为电压信号。这一点大大降低了器件的工作频率(20M/8=2.5MHz),相比GPU的2.5GHz,差了1000倍,这是制约算力重要因素。
四、其他重要问题
1.忆阻器如何改变电阻?
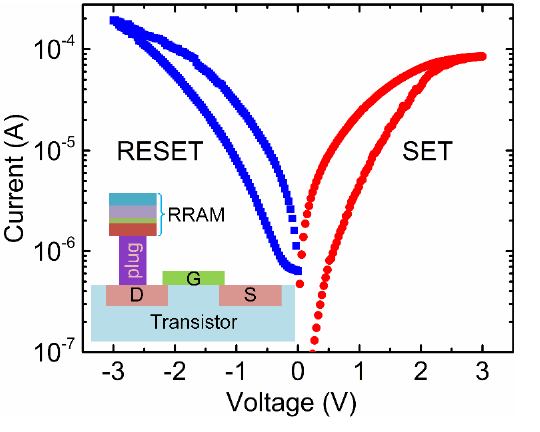 忆阻器RRAM通过plug(电热调制层,可以通过改变电导率和热导率来调制氧空位分布和阻变过程)与MOS管的漏极D相连。它有三种写操作:FORMING、SET、RESET。
忆阻器RRAM通过plug(电热调制层,可以通过改变电导率和热导率来调制氧空位分布和阻变过程)与MOS管的漏极D相连。它有三种写操作:FORMING、SET、RESET。
-
FORMING:源极S接地,栅极G接$V_g$,RRAM施加FORM电压,将器件由高电阻状态打到低电阻状态。
-
SET:源极S接地,栅极G接$V_g$,RRAM施加脉冲信号,一般2.0V,50ns,电导随脉冲个数的增大而增大。
-
RESET:RRAM接地,栅极G接$V_g$,源极S施加脉冲信号,一般-1.8V,50ns,电导随脉冲个数的增大而减小。
图中的横坐标是流过RRAM的电流随施加电压的变化关系,与一般的电阻(直线)相比,确实有明显的非线性和滞回性。
2.忆阻器阵列如何做权重更新?
对于理想阻变器件,线性度和对称性很好,可以通过控制施加的编程脉冲个数直接实现定量的更新。能降低硬件开销、实现低功耗、高能效的片上训练。
但是实际器件不仅存在明显的波动,而且非线性和非对称性显著,无法通过脉冲个数实现定量更新。只能确定更新的方向,然后每次只加一个set或reset脉冲。
3.算力与功耗分析
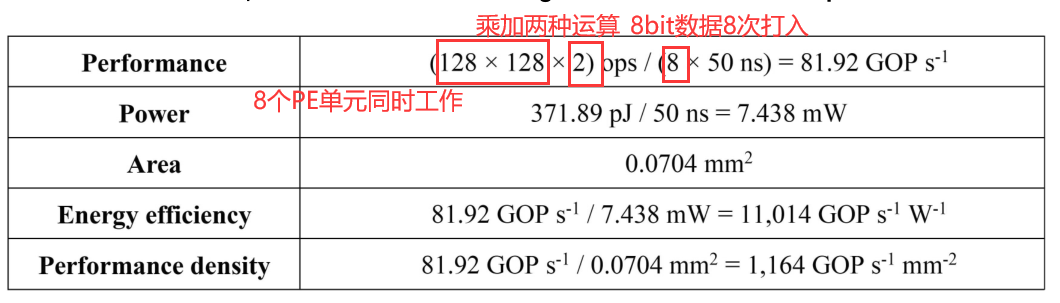
峰值算力为81.92$GOPs_{-1}$,功耗只有7.438mW。列出常见的CPU、GPU算力,以int8为基准:
| 型号 | 工作频率 | ALU单元 | 乘+加 | 功耗 | 算力 | 能效 |
|---|---|---|---|---|---|---|
| Intel Xeon E5-2699 v3 | 2.3G | 18* 2 * 64 | 2 | 145w | 10.6TOPs | 73GOPs/w |
| TPU | 0.7G | 64k | 2 | 384w | 90TOPs | 240GOPs/w |
| NVIDIA Tesla V100 | 1.455G | 5120*4 | 2 | 300w | 60TOPs | 200GOPs/w |
| 忆阻器阵列 | 20M/8 | 128*128 | 2 | 7.4mw | 82GOPs | 11014GOPs/w |
可见,忆阻器的算力瓶颈在频率上,而它的功耗是真的低!
五、可以做的工作
1、如何增加通用性?
文章介绍的是MNIST识别的应用,是否可以通过编译,做更加复杂的如tramformer等网络的训练?
2、在线训练能力提高?
文章的权重是在GPU上训练好的,类似“迁移学习”,能否不依赖GPU,独立做所有的训练?
3、训练好的数据如何更快map到rram阵列?
文章的权重map到rram上非常耗时耗力,灵活性不强,能否有更加高效的映射方法? ###4、设计低功耗,面积更小的ADC? ADC占总体功耗的90%,每一层都需要转换,是否可以用模拟电路完成pooling和Activation的功能。设计更低功耗的ADC也相当重要。
###5、RRAM结合异步电路会有什么火花? 人脑没有全局时钟,并具有记忆功能,RRAM与异步电路结合,是否有新场景?
您好,我最近也在学习这篇文章,请问这里的sample&hold有什么作用是如何构成的
对了,还有一个问题就是他的阵列中,比如子线的另一端是没有接的,那就是要悬空吗
那是位线吧,推理的时候高阻态,训练的时候可以增加脉冲信号修改权重
好像是积分单元,电流需要通过积分单元转化为电压,然后将钳位电压给ADC
希望能够得到您的解答,谢谢
有关于实现忆阻器神经网络的代码吗
会有一些基于python或c++的仿真器,模拟器件行为
同求,请问找到了吗