rk3399pro部署unet
最近参与一个项目,需要利用unet做焊点检测,unet最终要部署在Rockchip的rk3399pro嵌入式系统里,该系统内部有神经网路加速器,但需要先转成.rknn的格式。
RK3399Pro NPU Manual提供了入门指导,里面的RKNN toolkit 包含了样例和转换工具。我的unet版本是参考github头像匹配的pytorch版本。
一、出师不利
样例提供了torchvision上resnet_18的python版本,能够成功转成rknn格式,代码如下:
import numpy as np
import cv2
from rknn.api import RKNN
import torchvision.models as models
import torch
if __name__ == '__main__':
net = models.resnet_18(pretrained=True)
net.eval()
trace_model = torch.jit.trace(net, torch.Tensor(1, 3, 224, 224))
trace_model.save('./resnet_18.pt')
model = './resnet_18.pt'
input_size_list = [[3,224,224]]
# Create RKNN object
rknn = RKNN()
# pre-process config
print('--> config model')
rknn.config(channel_mean_value='123.675 116.28 103.53 58.395', reorder_channel='0 1 2')
print('done')
# Load pytorch model
print('--> Loading model')
ret = rknn.load_pytorch(model=model, input_size_list=input_size_list)
if ret != 0:
print('Load pytorch model failed!')
exit(ret)
print('done')
# Build model
print('--> Building model')
ret = rknn.build(do_quantization=False, dataset='./dataset.txt')
if ret != 0:
print('Build pytorch failed!')
exit(ret)
print('done')
# Export rknn model
print('--> Export RKNN model')
ret = rknn.export_rknn('./resnet_18.rknn')
if ret != 0:
print('Export resnet_18.rknn failed!')
exit(ret)
print('done')
这里有个关键函数,torch.jit.trace,JIT表示Just In Time Compilation,即时编译。它是Python和C++的桥梁,我们可以使用python训练模型,然后通过JIT将模型转为与语言无关的静态图,供C++调用,能非常方便得部署到树莓派、IOS、Android等设备。
静态图大概长这样:
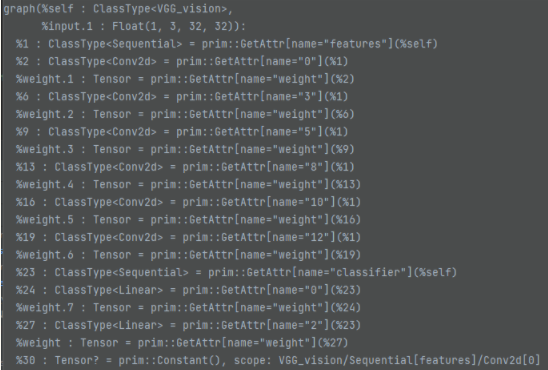
我一开始先想部署自己训练的VGG模型,网络尽量接近torchvision_models的样例,定义如下:
import torch.nn as nn
import torch
class VGG(nn.Module):
def __init__(self):
super(VGG, self).__init__()
self.conv1 = nn.Conv2d(3, 32, 3, 1, 1,bias=False)
self.relu = nn.ReLU(inplace=True)
self.conv2_1 = nn.Conv2d(32, 64, 3, 1, 1,bias=False)
self.max_pool2d = nn.MaxPool2d(kernel_size=2,stride=2)
self.conv2_2 = nn.Conv2d(64, 64, 3, 1, 1,bias=False)
self.conv3_1 = nn.Conv2d(64, 128, 3, 1, 1,bias=False)
self.conv3_2 = nn.Conv2d(128, 128, 3, 1, 1,bias=False)
self.conv3_3 = nn.Conv2d(128, 128, 3, 1, 1,bias=False)
self.fc1 = nn.Linear(2048, 128,bias=False)
self.fc2 = nn.Linear(128, 10,bias=False)
def forward(self, x):
out = self.relu(self.conv1(x))
out = self.max_pool2d(out)
out = self.relu(self.conv2_1(out))
out = self.relu(self.conv2_2(out))
out = self.max_pool2d(out)
out = self.relu(self.conv3_1(out))
out = self.relu(self.conv3_2(out))
out = self.relu(self.conv3_3(out))
out = self.max_pool2d(out)
out = torch.flatten(out,1)
out = self.relu(self.fc1(out))
out = self.fc2(out)
return out
结果奇怪的是,当运行到ret = rknn.load_pytorch(model=model, input_size_list=input_size_list),一直报错:
AttrubuteError:'NoneType' object has no attribute 'get_input_layers'
rknn.load_python函数是以动态库的方式给的,pycharm debug模式看不到源码,产看静态图,也找不到input_layers这种信息,为之奈何? 竟然官网的样例可以跑通,那一定是模型定义的问题,因此反复比较我的VGG模型和torchvision models上alexnet的区别,终于发现了,不同,虽然有点不理解,但最终还是跑通了:
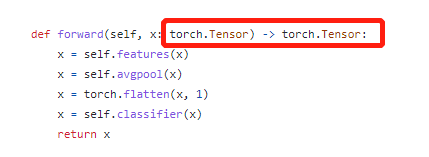
官网forward函数添加了输入输出类型的定义,torch.Tensor!?这还用定义?这不明摆的吗,真是服了。
二、大Boss
跑通VGG,说明卷积、下采样等函数是支持的,Unet与之相比,只增加了两点:
- 跨层的拼接:torch.cat([x2,x1],dim=1)
- 上采样函数:nn.Upsample()
unet模型定义如下:
import torch
import torch.nn as nn
class DoubleConv(nn.Module):
"""(convolution => [BN] => ReLU) * 2"""
def __init__(self, in_channels, out_channels):
super().__init__()
self.double_conv = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
)
def forward(self, x:torch.Tensor)->torch.Tensor:
return self.double_conv(x)
class Down(nn.Module):
"""Downscaling with maxpool then double conv"""
def __init__(self, in_channels, out_channels):
super().__init__()
self.maxpool_conv = nn.Sequential(
nn.MaxPool2d(2),
DoubleConv(in_channels, out_channels)
)
def forward(self, x:torch.Tensor)->torch.Tensor:
return self.maxpool_conv(x)
class Up(nn.Module):
"""Upscaling then double conv"""
def __init__(self, in_channels, out_channels, bilinear=True):
super().__init__()
self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)
self.conv = DoubleConv(in_channels, out_channels)
#def forward(self, x1:torch.Tensor, x2:torch.Tensor)->torch.Tensor:
def forward(self, x: torch.Tensor) -> torch.Tensor:
x = self.up(x)
return self.conv(x)
class OutConv(nn.Module):
def __init__(self, in_channels, out_channels):
super(OutConv, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=1)
def forward(self, x:torch.Tensor)->torch.Tensor:
return self.conv(x)
CHANNEL = 64
class UNet(nn.Module):
def __init__(self, n_channels, n_classes, bilinear=True):
super(UNet, self).__init__()
self.n_channels = n_channels
self.n_classes = n_classes
self.bilinear = bilinear
self.inc = DoubleConv(n_channels, CHANNEL)
self.down1 = Down(CHANNEL, CHANNEL * 2)
self.down2 = Down(CHANNEL * 2, CHANNEL * 4)
self.down3 = Down(CHANNEL * 4, CHANNEL * 8)
self.down4 = Down(CHANNEL * 8, CHANNEL * 8)
self.up1 = Up(CHANNEL * 16, CHANNEL * 4, bilinear)
self.up2 = Up(CHANNEL * 8, CHANNEL * 2, bilinear)
self.up3 = Up(CHANNEL * 4, CHANNEL, bilinear)
self.up4 = Up(CHANNEL * 2, CHANNEL, bilinear)
self.outc = OutConv(CHANNEL, n_classes)
def forward(self, x):
x1 = self.inc(x)
x2 = self.down1(x1)
x3 = self.down2(x2)
x4 = self.down3(x3)
x5 = self.down4(x4)
x = self.up1(x5, x4)
x = self.up2(x, x3)
x = self.up3(x, x2)
x = self.up4(x, x1)
logits = self.outc(x)
return logits
跨层拼接的其实可以参考resnet_18,将原来unet合并的up层展开为上采样+双层卷积,不是硬伤。 难点就在上采样函数,单独提取出来,转换上采样函数,一直报这样的错误:
int() argument must be a string , a bytes-like object or a number, not 'NoneType'
这是啥玩意,pycharm在debug模式下,终于找到torch.Upsample()最后调用的函数torch._C._nn.upsample_bilinear2d()
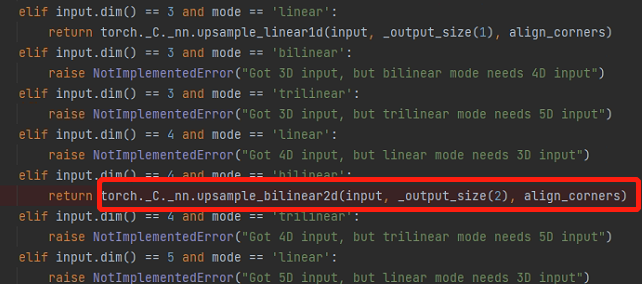
它会经过一系列判断,获得输入图的维度dim和尺寸信息,最后调用这个内嵌函数。然而,获取输出图像大小时,它调用了input.size()函数,这是报错的关键,静态图怎么要调用这个函数呢?输入确定的情况下,这个大小应该也是确定的吧,直接换成确定大小就行。

知道症结之后,针对跨层拼接和上采样,对模型稍加修改(输入特征图定为544x544):
- 删除了Up 模块,拆分进forward
- 上采样函数直接用torch._C._nn.upsample_bilinear2d替换
- 上采样的输出尺寸直接给固定值
""" Full assembly of the parts to form the complete network """
import torch
import torch.nn as nn
class DoubleConv(nn.Module):
"""(convolution => [BN] => ReLU) * 2"""
def __init__(self, in_channels, out_channels):
super().__init__()
self.double_conv = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
)
def forward(self, x:torch.Tensor)->torch.Tensor:
return self.double_conv(x)
class Down(nn.Module):
"""Downscaling with maxpool then double conv"""
def __init__(self, in_channels, out_channels):
super().__init__()
self.maxpool_conv = nn.Sequential(
nn.MaxPool2d(2),
DoubleConv(in_channels, out_channels)
)
def forward(self, x:torch.Tensor)->torch.Tensor:
return self.maxpool_conv(x)
class OutConv(nn.Module):
def __init__(self, in_channels, out_channels):
super(OutConv, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=1)
def forward(self, x:torch.Tensor)->torch.Tensor:
return self.conv(x)
CHANNEL = 64
INPUT_SIZE = 544
class UNet(nn.Module):
def __init__(self, n_channels, n_classes, bilinear=True):
super(UNet, self).__init__()
self.n_channels = n_channels
self.n_classes = n_classes
self.bilinear = bilinear
self.inc = DoubleConv(n_channels, CHANNEL)
self.down1 = Down(CHANNEL, CHANNEL * 2)
self.down2 = Down(CHANNEL * 2, CHANNEL * 4)
self.down3 = Down(CHANNEL * 4, CHANNEL * 8)
self.down4 = Down(CHANNEL * 8, CHANNEL * 8)
self.conv1 = DoubleConv(CHANNEL * 16, CHANNEL * 4)
self.conv2 = DoubleConv(CHANNEL * 8, CHANNEL * 2)
self.conv3 = DoubleConv(CHANNEL * 4, CHANNEL)
self.conv4 = DoubleConv(CHANNEL * 2, CHANNEL)
self.outc = OutConv(CHANNEL, n_classes)
def forward(self, x:torch.Tensor)->torch.Tensor:
x1 = self.inc(x)
x2 = self.down1(x1)
x3 = self.down2(x2)
x4 = self.down3(x3)
x = self.down4(x4)
x = torch._C._nn.upsample_bilinear2d(x, [INPUT_SIZE//8, INPUT_SIZE//8], True)
x = self.conv1(torch.cat([x4,x],dim=1))
x = torch._C._nn.upsample_bilinear2d(x, [INPUT_SIZE//4, INPUT_SIZE//4], True)
x = self.conv2(torch.cat([x3,x],dim=1))
x = torch._C._nn.upsample_bilinear2d(x, [INPUT_SIZE // 2, INPUT_SIZE // 2], True)
x = self.conv3(torch.cat([x2,x],dim=1))
x = torch._C._nn.upsample_bilinear2d(x, [INPUT_SIZE , INPUT_SIZE ], True)
x = self.conv4(torch.cat([x1,x],dim=1))
x = self.outc(x)
return x
这样就可以快乐的完成模型转换了!
感谢大神分享,我最近也想玩rk1808,想知道,unet在rk上有做量化吗?运行耗时怎么样?
模型转换的时候可以加量化选项,npu自带功能。量化后加速挺快。耗时得看计算量,最新的博文有提到