大佬的矩阵乘法加速
感谢这篇博文的分享,原理讲得很清楚。大佬是怎么优雅实现矩阵乘法的? github 源码,核心代码用汇编,"sgemm_kernel_x64_fma.S"
由于之前用过avx256指令集做过加速,也了解cpu亲和性方面的知识,于是我便在三台机器上做了尝试,理清了不少东西,顺便记录一番。
大佬的配置如下,计算性能时有两点需要注意:
- 为什么是8x2? 利用了avx256寄存器,一次可以处理8个32bit 的float类型数据,2表示乘、加两种运算。
- 为什么要加两下?单个逻辑核有超标量,一个周期可以处理两个计算指令。理由是“main.c”函数中有绑定cpu亲和性的操作:
thread_bind(0),因此只用了一个逻辑核。

实验一 :性能测试
在自己电脑的虚拟机测试(AMD Ryzen pro 2500u @2GHz):
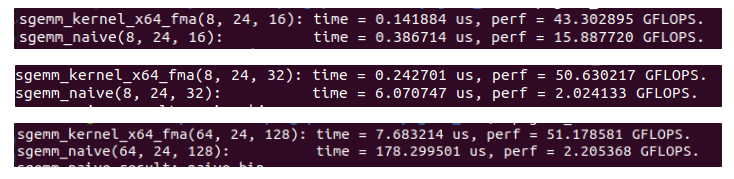 (8,24,16)表示A、B矩阵大小分别为8x16,16x24。总运算量:8x16x24x2=6144次乘加。除以运算时间就是性能:
(8,24,16)表示A、B矩阵大小分别为8x16,16x24。总运算量:8x16x24x2=6144次乘加。除以运算时间就是性能:
另外两个服务上也做了测试:
 貌似第二个服务器的结果更加符合预期,预计峰值
貌似第二个服务器的结果更加符合预期,预计峰值
实验二:Cache
产生差异的原因会和cache有关吗?感觉关系不大,但也顺便探索了一番。
自己笔记本的cache如下,L1=384kB,L2=2.0MB,L3=4.0MB。同时这个cpu是4核8线程,cache如何分布在核上的?
 可以用如下指令查看各级cache的具体分布:
可以用如下指令查看各级cache的具体分布:
cat /sys/devices/system/cpu/cpu0/cache/index0/size
32k
cat /sys/devices/system/cpu/cpu0/cache/index1/size
64k
cat /sys/devices/system/cpu/cpu0/cache/index2/size
512k
cat /sys/devices/system/cpu/cpu0/cache/index4/size
4096k
发现竟然还有四个index,用指令:getconf -a |grep CACHE继续查看
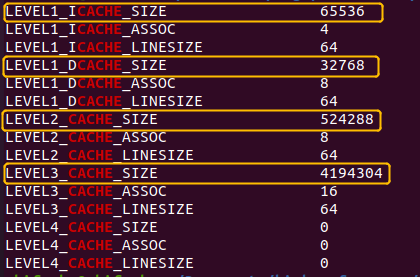 发现L1分为指令缓存65536B和数据缓存32768B,为什么不是384kB?
发现L1分为指令缓存65536B和数据缓存32768B,为什么不是384kB?
正是因为有4个物理核,上图显示的是一个线程享有的L1,L2,L3。统计4个核的L1,L2,L3(共用),得到如下清晰的结构:
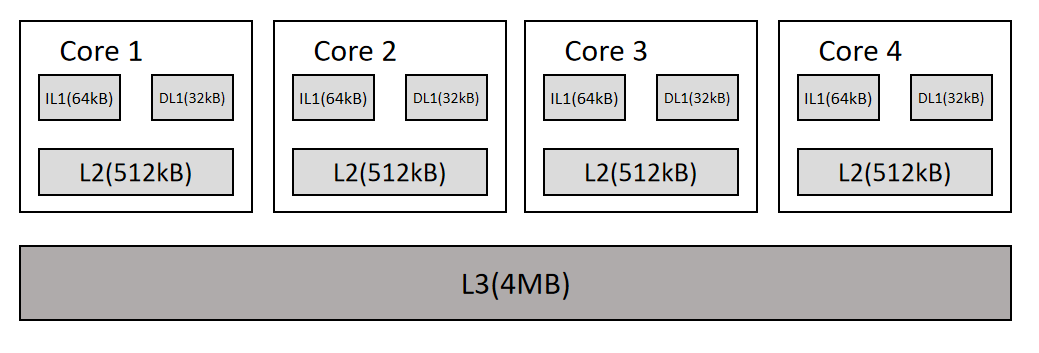 这里需要注意两点:
这里需要注意两点:
- IL1和DL1共同构成L1,四个96kB的L1总共有384kB。
- 这里的k不是1000,而是1024。
用这个指令交叉验证:lscpu
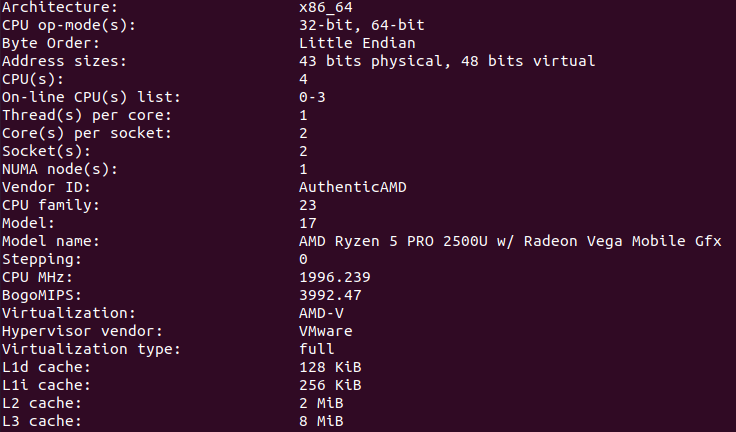
发现L1d,L1i,L2都符合预期,但L3竟然不是4M,这点不得其解。
总结
经过这番探索,结合之前cpu亲和性的文章,对其结构有更深刻的理解,并能通过linux指令查看验证结构。