捡到RoCC的贝壳
Chipyard Docker——坑外有坑 搭好chipyard的环境之后,便开始做一些简单开发,Berkeley提供了用户定制协处理器的接口,方便在Rocketchip上拓展一些自定义的硬件加速模块。
一、RoCC入门资料
整理过一些RoCC(Rocket of Costum)开发的实用资料:
二、RoCC模块
写了一个矩阵向量乘法的加速器,增加了三条核心拓展指令:
- push : 从内存传入向量至RoCC
- mvm : 执行矩阵向量乘法(权重矩阵已提前写好)
- save : 从RoCC传出结果至内存
完成功能测试之后,希望性能,于是在RoCC_mvm指令前后添加时钟数计时,结果发现打印的周期数远远小于估算的周期数,最终计算结果是对的。
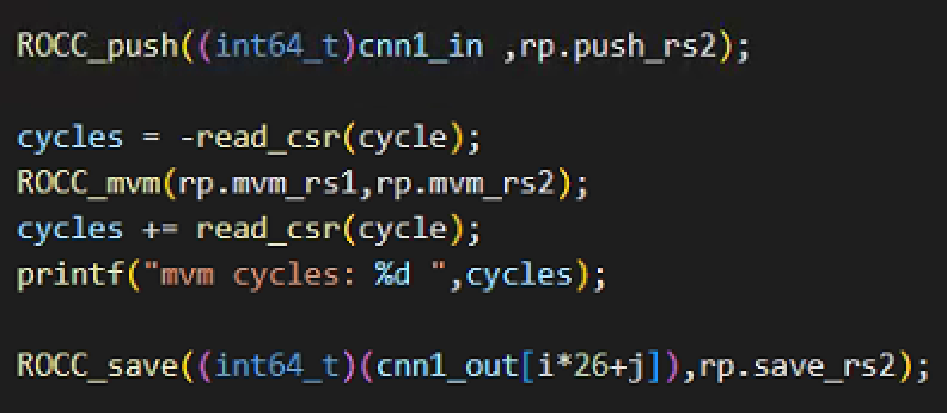
难道gcc -O2 优化改变了指令执行顺序?反汇编查看执行的指令,确实也是这个顺序!为之奈何?——波形时序图。
调出几个关键信号:
- inst_real: 实际执行的指令
- RoCC : RoCC内部状态机状态
- inst_pre:这是自己预想的时序图


发现执行mvm指令之后,RoCC进入mvm状态,但计算还没结束,cpu紧接着执行后面的读时钟和打印指令,最后计算完毕之后,才执行save,保证了计算结果的正确性,但计时不正确。
三、捡到贝壳
之前一致觉得RoCC运算的时候,流水线会停滞,没想到CPU还是可以做其他事情的,那么是否可以在RoCC计算的时候,CPU做一些准备数据的工作呢,这样可以充分利用计算资源,实现完美的时间管理!
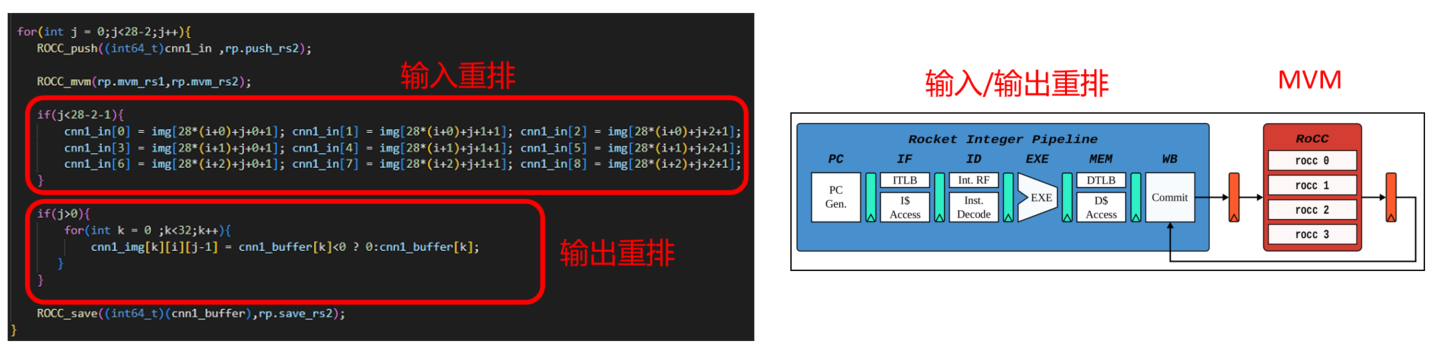
四、知其所以
为什么是这样的时序呢?之前做芯来科技E203协处理器的时候,确实和预想的逻辑一样,RocketChip为什么不同呢?看内存一致性模型相关的资料,结合官方手册The RISC-V Instruction Set Manual,找到一些线索。
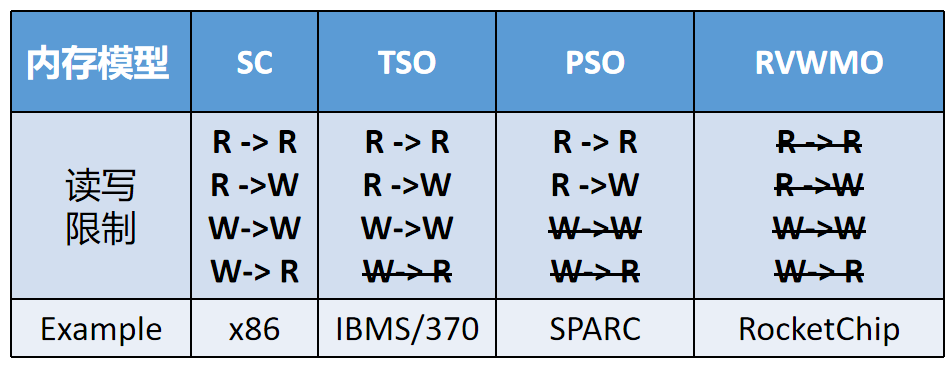
内存一致性模型是描述多核访存的时候,应该遵守什么样的规则,不同的规则对应不同的模型,不同的模型在性能、编程难度等方面也不同。访存的读写指令在流水线上是多周期完成的,为了避免出错,可以有这样一个模型:读或写完成之后,再写或读下一条指令。这就是SC(Sequential consistency,顺序一致性模型)。按这个模型设计的处理器,编程友好,但性能会差一些。
为了提高性能,需要对读写放宽限制。为了充分释放CPU的计算能力,读比写的优先级会更高,因此可以放宽“写完之后再读”的限制:如果读写地址不同,还没写完毕,就可以执行下一条读指令。这就是TSO(Total Store Order,强顺序模型)。
如果放宽“写完之后再写”的限制,那么会得到PSO模型(partial store ordering)。
如果完全放宽读写限制,那么会的到WMO(weak memory ordering,弱一致性模型),而这里的Rocketchip就是采用RVWMO模型。缺少了这些限制,性能能够提升,但为了保证程序执行的正确性,RISC-V提供了同步指令“fence”。
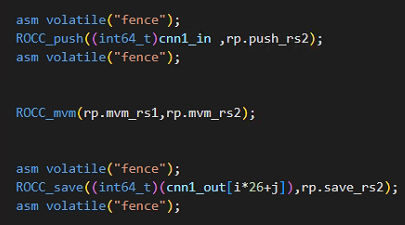
所以为了保证我的拓展指令功能正确,需要在push和save指令前后添加同步指令:push完毕之后,才能执行计算,计算完毕之后,才能保存数据。这样才可以保证功能的正确性:
以上的模型可以用下表总结:
有关内存一致性模型的内容很复杂,不知让大佬们掉了多少头发,只能简单介绍点皮毛,还很可能理解错~
无意中从计时的错误发现一种提高性能的方法,还是挺神奇的。
同学你好,我是中科院的学生。和这个方向一致,能加个微信吗?我的:lipewx008